



Hadoop 2.8.5一键部署:完全分布式实战指南
发布日期:2024-09-24 阅读数:1689
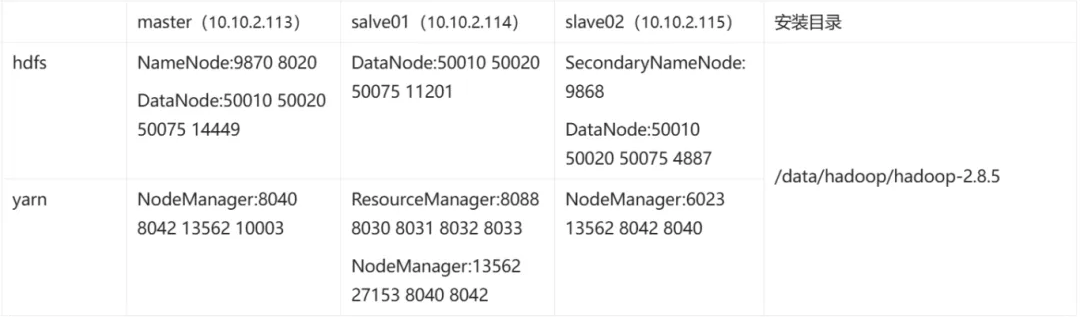
集群安装规化
#生成秘钥
ssh-keygen
将三台机器的公钥/root/.ssh/id_rsa.pub都复制到/root/.ssh/authorized_keys
root@master:~# cat /etc/hosts
127.0.0.1 localhost
10.10.2.113 master
10.10.2.114 slave01
10.10.2.115 slave02
apt install openjdk-8-jkd-headless
vim ~/.bashrc
# java config
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
source ~/.bashrc
root@master:~# java -version
openjdk version "1.8.0_412"
OpenJDK Runtime Environment (build 1.8.0_412-8u412-ga-1~22.04.1-b08)
OpenJDK 64-Bit Server VM (build 25.412-b08, mixed mode)
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gz
tar -zxvf hadoop-2.8.5.tar.gz -C /data/hadoop
vim ~/.bashrc
# HADOOP PATH
export HADOOP_HOME=/data/hadoop/hadoop-2.8.5
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source ~/.bashrc
root@ubuntu:~# hadoop version
Hadoop 2.8.5
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 0b8464d75227fcee2c6e7f2410377b3d53d3d5f8
Compiled by jdu on 2018-09-10T03:32Z
Compiled with protoc 2.5.0
From source with checksum 9942ca5c745417c14e318835f420733
This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-2.8.5.jar
<configuration>
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<!-- 指定 Hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/hadoop-2.8.5/data</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为 root-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 设置集群用户权限 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
<configuration>
<!-- nn(NameNode) web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<!-- 2nn(SecondaryNameNode) web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave02:9868</value>
</property>
</configuration>
<configuration>
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>slave01</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://master:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
#JAVA_HOME如实填写java路径
export JAVA_HOME=/usr/local/jdk1.8.0_161
#hadoop默认ssh 22端口,如果集群机器不是22端口需要修改
export HADOOP_SSH_OPTS="-p 10022"
vi $HADOOP_HOME/etc/hadoop/slaves
# 添加你的主机
master
slave1
slave2
# 分发环境变量
rsync -r ~/.bashrc slave01:~/.bashrc
rsync -r ~/.bashrc slave02:~/.bashrc
# 分发Hadoop
scp -r /data/hadoop/hadoop-2.8.5 slave01:/data/hadoop
scp -r /data/hadoop/hadoop-2.8.5 slave02:/data/hadoop
source ~/.bashrc

hdfs namenode-format
# 在主节点中运行
start-dfs.sh
# 在 ResourceManager 节点中运行
start-yarn.sh
# 或者
# 在主节点中运行
start-all.sh
# 在 ResourceManager 节点中运行
start-yarn.sh
# 在主节点中启动历史服务器
mr-jobhistory-daemon.sh start historyserver



新闻搜索

相关新闻



































































云安全风险发现,从现在开始



