Zabbix 使用时的那些注意事项
Zabbix 作为主流的开源监控工具,凭借灵活的监控能力和丰富的功能,被广泛用于 IT 基础设施与业务系统监控。但在实际使用中,若忽视细节,很容易出现监控不准、告警泛滥、性能卡顿等问题。本文将从架构规划到日常运维,梳理 Zabbix 使用时需重点关注的注意事项。
【PART01】架构规划:别让 “小监控” 卡了 “大系统”
Zabbix 的架构弹性强,可从单服务器部署扩展到分布式集群,但架构设计若不合理,会成为后期监控的 “瓶颈”。
单服务器部署要控制 “监控规模”。
很多新手初期图省事直接用单台 Zabbix Server,却忽略了它的承载上限 —— 通常单节点稳定支持的监控项在 10 万以内(受服务器 CPU、内存影响)。若盲目接入数百台设备、每台配置上百个监控项,会导致 Server 端数据库写入拥堵,监控数据采集延迟甚至丢失。建议初期就估算规模:按 “每台设备平均 50 个监控项” 算,200 台设备就需预留 1 万监控项容量,若超 500 台设备,优先考虑 “Zabbix Server+Proxy” 的分布式架构。
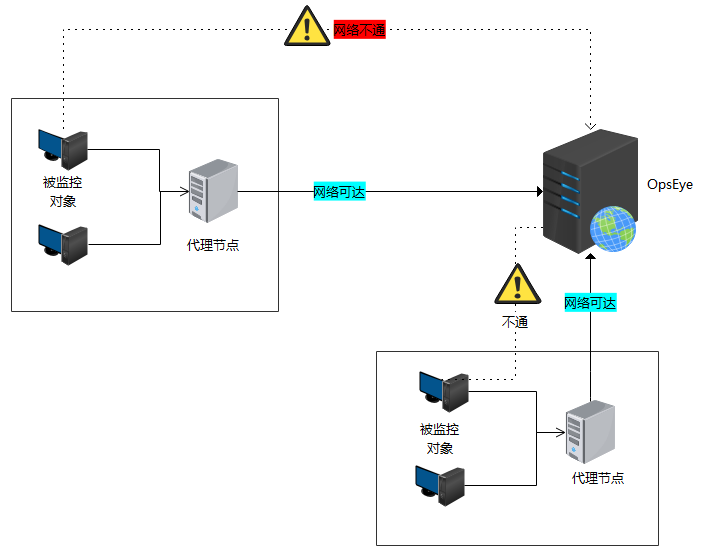
Proxy 节点部署要 “就近原则”。
分布式场景中,Proxy 的作用是代理采集数据,减轻 Server 压力。部署时别随意将 Proxy 堆在机房角落 —— 若监控对象分布在多地域(如北京、上海机房),应在每个地域部署本地 Proxy,避免跨地域采集导致的网络延迟(比如上海的服务器让北京的 Proxy 采集,数据传输耗时可能从 10ms 增至 100ms,影响监控实时性)。另外,Proxy 与 Server 的通信需单独规划带宽,每台 Proxy 每小时约产生 100MB~500MB 数据(按 1 万监控项算),避免因带宽不足导致数据积压。
【PART02】监控项配置:别让 “无效指标” 拖垮性能
监控项是 Zabbix 的 “数据源头”,但不少人陷入 “越多越好” 的误区,结果指标冗余还占资源。
先做 “监控项减法”。
默认模板里的监控项未必都需要:比如监控 Windows 服务器时,Zabbix 自带模板可能包含 “注册表键值”“系统服务详细状态” 等冷门监控项,若业务用不上,需手动禁用。更关键的是避免 “重复监控”—— 比如既用 “icmp ping” 监控主机存活,又在 Agent 里加 “system.run [ping -c 1 127.0.0.1]” 的自定义监控项,两者功能重叠,徒增采集压力。建议按 “核心需求” 筛选:服务器优先保留 “CPU 使用率”“内存占用”“磁盘 IO” 等基础指标,业务服务聚焦 “进程存活”“端口监听”“响应时间” 等关键指标。
警惕 “高频率采集陷阱”。
监控项的 “更新间隔” 不是越小越好:比如将 “Web 页面响应时间” 的采集间隔设为 1 秒,看似数据更实时,但每台 Agent 每秒都要发起 HTTP 请求,不仅占用服务器资源,还会让 Zabbix 数据库写入量激增(1 个监控项 1 秒 1 条数据,1000 个监控项 1 小时就 360 万条)。合理的做法是 “按指标重要性分级”:核心指标(如支付接口响应时间)设为 5~10 秒间隔,非核心指标(如服务器磁盘温度)设为 30~60 秒间隔;临时排查问题时,可临时缩短间隔,排查结束后改回默认,避免长期高频率采集。
自定义监控项要 “避坑标签与键值”。
自定义监控项时,标签(Key)若设计不当,会导致后期维护混乱:比如监控不同业务的接口响应时间,别用 “api_response_time1”“api_response_time2” 这种模糊键值,建议用 “api_response_time {service=order}”“api_response_time {service=pay}” 的格式,通过标签区分业务,既清晰又方便聚合查询。另外,自定义脚本别返回 “非数值” 结果 —— 若脚本偶尔输出 “timeout” 而非数字,Zabbix 会记录 “不支持的值”,导致数据断档,需在脚本里做异常处理(比如超时则返回 - 1,再在触发器里设 “值 =-1 则告警”)。
【PART03】触发器与告警:别让 “噪音” 掩盖 “真问题”
触发器是 Zabbix 的 “告警开关”,但不少团队因配置粗糙,每天收到上百条告警,最后反而漏了关键问题。
触发器阈值要 “接地气”。
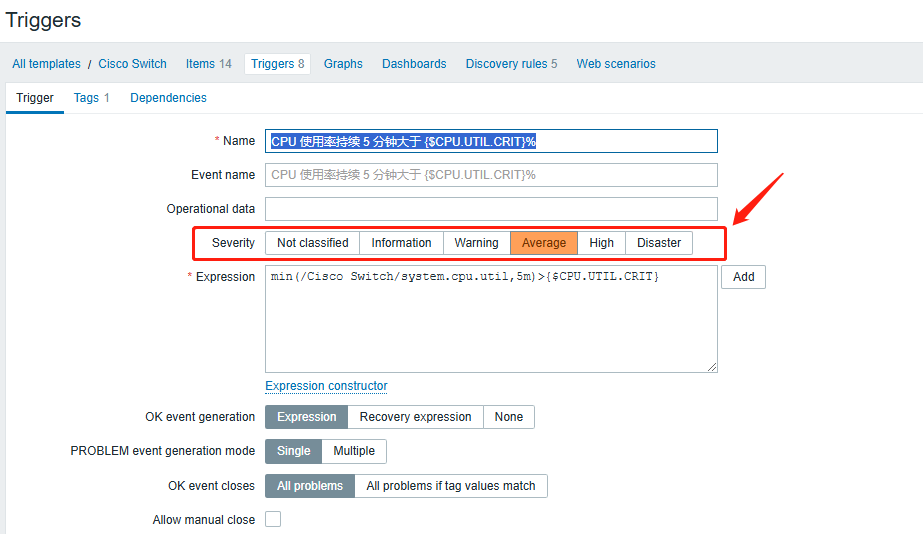
别照搬网上的 “通用阈值”:比如将 “CPU 使用率 > 80%” 设为告警,但对数据库服务器来说,CPU 长期维持在 70%~85% 可能是常态(正常业务负载),按 80% 告警会频繁误报;而对轻量应用服务器,CPU 突增到 60% 可能已异常。正确的做法是 “先观察基线”:让监控运行 1~2 周,统计指标的正常波动范围(比如通过 Zabbix 的 “历史数据统计” 看 CPU 平均使用率是 40%,峰值 65%),再将阈值设为 “峰值 + 10%~20%”(如 75%),或用 “环比 / 同比” 阈值(如 “CPU 使用率 5 分钟内增长超过 50%”),更贴合实际业务。
用 “依赖关系” 抑制连锁告警。
IT 系统是联动的:若核心交换机宕机,所有接入该交换机的服务器都会 “ping 不通”,此时若没做依赖配置,Zabbix 会同时发 “交换机宕机”“服务器 A 不可达”“服务器 B 不可达” 等十几条告警,淹没核心问题。可在 Zabbix 里配置 “触发器依赖”:让 “服务器不可达” 触发器依赖 “交换机存活” 触发器,当交换机告警触发时,自动抑制所有依赖它的服务器告警,只保留根源告警。
告警媒介别 “一刀切”。
不同级别告警要用不同通知方式:比如 “服务器磁盘满” 是紧急告警,需同时发邮件、企业微信并打电话;而 “内存使用率略高(如 85%)” 是预警,只需发企业微信即可。在 Zabbix 的 “告警媒介” 里可按 “触发器 severity(严重级别)” 分层: severity 设为 “灾难 / 高危” 的,联动电话 + 短信;设为 “警告 / 信息” 的,只发应用内通知。另外,别让所有告警都堆给全团队 —— 通过 “用户组” 分配责任:服务器告警给运维组,业务接口告警给开发组,避免 “全员收到告警却没人跟进”。
【PART04】数据库与运维:别让 “存储” 成 “短板”
Zabbix 的所有监控数据都存在数据库(默认 MySQL/PostgreSQL)里,数据库若出问题,整个监控系统会 “瘫痪”。
定期做 “数据清理”。
Zabbix 默认会保留所有历史数据,但监控项多了,数据库会膨胀得很快:10 万监控项每天约产生 8.6 亿条数据(按 30 秒间隔算),1 个月就占几十 GB 甚至上百 GB 磁盘。需在 “Administration→General→Housekeeping” 里配置自动清理规则:历史数据(history 表)保留 7~15 天即可(日常排查问题足够),趋势数据(trends 表)可保留 3~6 个月(用于长期分析);若用 MySQL,建议开启 “表分区”(按时间分区 history 表),避免清理时全表锁表导致写入卡顿。
警惕 “数据库性能瓶颈”。
当监控项超 5 万时,数据库的写入压力会明显增大 —— 若 MySQL 用默认配置(innodb_buffer_pool_size=128M),会频繁出现 “读写等待”。需针对性优化:把 innodb_buffer_pool_size 调大(至少设为服务器内存的 50%),让更多数据缓存在内存;开启 binlog 时用 “ROW” 格式(避免 STATEMENT 格式的写入延迟);定期优化表(比如每周执行 “OPTIMIZE TABLE history”),清理碎片。
Zabbix 的好用与否,关键不在 “功能多全”,而在 “细节是否落地”。从架构规划时的容量估算,到监控项的精准筛选,再到告警的降噪优化,每个环节踩坑都可能让监控 “失效”。避开这些注意事项,才能让 Zabbix 真正成为 IT 系统的 “预警雷达”,而非 “麻烦制造者”。
新闻搜索