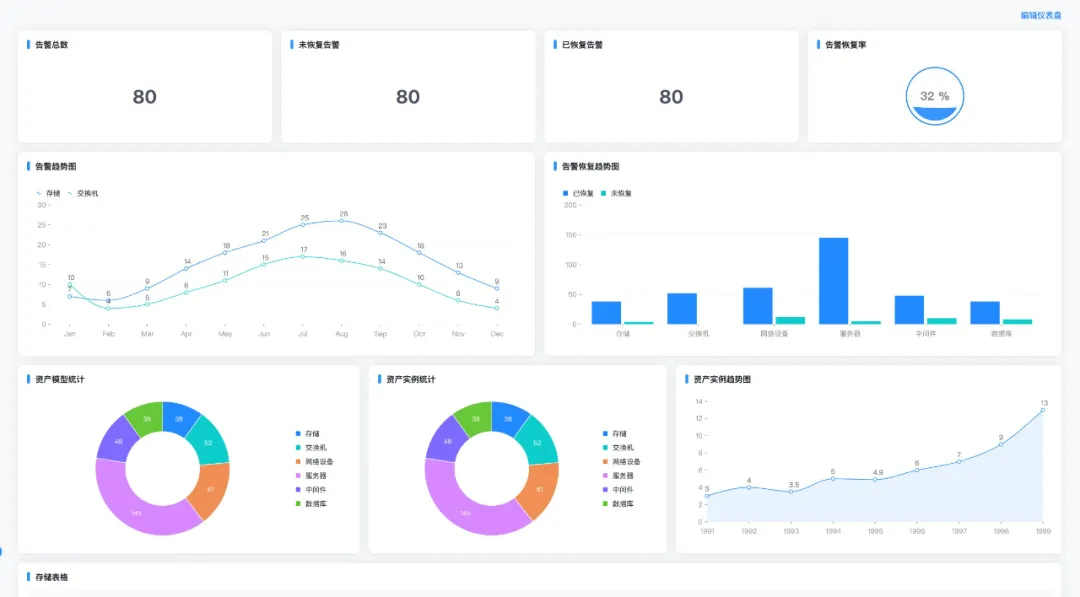
历史告警:运维监控体系中被低估的 “决策基石”
当前企业IT 架构日趋复杂,多数运维团队聚焦实时告警 “应急响应”,却将历史告警视作 “过期日志”,导致运维陷入 “被动救火” 循环。本文解析历史告警的价值与应用,助力构建前瞻性监控体系。
重视历史告警是运维理念升级的必然。实时告警解决“当下问题”,却无法避免 “重复踩坑”—— 如数据库连接数超限、缓存雪崩等问题反复出现,根源在于未从历史告警中挖规律、总结经验。
复杂系统故障多是隐患长期积累的爆发。某业务接口响应时间一周内从 50ms 增至 500ms,期间每日触发 “响应时间告警”,若仅临时处理,最终会导致业务中断。而历史告警记录系统从 “健康” 到 “故障” 的演变,唯有分析才能实现 “事前预防”。
同时,历史告警为业务决策提供支撑。例如电商大促前,需判断资源是否充足,过去大促的 CPU、内存等告警数据,是精准预测资源需求、提前扩容的关键依据。
“平均故障恢复时间(MTTR)” 是运维核心指标,历史告警能显著缩短 MTTR。复杂系统故障具有 “关联性”,仅靠实时告警难理清 “因果链”,而历史告警可提供完整线索。某互联网企业支付系统凌晨触发 “服务不可用告警”,实时数据显示 “接口调用失败”,运维人员查看历史告警发现,过去一周该系统数据库服务器每天凌晨 1 点触发 “内存使用率超 90% 告警”,且呈上升趋势,据此快速定位根源是数据库内存不足导致连接拒绝,15 分钟恢复服务,排查时间较以往缩短 60%。
针对 “间歇性故障”(如偶发接口超时、磁盘 IO 峰值),历史告警记录每次故障的发生时间、触发条件、关联指标,运维人员通过对比共性(如均发生在数据备份时段),可精准定位根源,避免故障反复。
云原生时代 “弹性扩容” 需量化依据,历史告警是 “按需扩容” 的关键支撑。某短视频平台晚间 8-10 点用户活跃,白天低谷,未分析历史告警前采用 “固定扩容”—— 下午 6 点增倍服务器,凌晨 2 点缩减,导致白天资源利用率仅 30%。后来运维团队分析 3 个月历史告警发现,仅当服务器 CPU 使用率持续 10 分钟超过 80% 时才触发 “CPU 阈值告警”,且晚间峰值 85%、白天 40% 以下,据此调整策略:连续 3 天同一时段 CPU 接近 75% 才扩容,资源利用率提升 40%,每月节省云成本 20 万元。
此外,历史告警还可用于数据库、缓存、网络带宽的容量规划。如通过分析数据库 “连接数告警” 历史数据,预测未来半年连接数增长趋势,提前调整配置或分库分表,避免因连接数不足导致业务中断。
每一次故障都是学习机会,历史告警是 “故障经验” 转化为 “知识库” 的核心素材。通过整理分析历史告警,可建立 “故障模式库”,记录告警特征、排查流程、解决方案。某金融企业核心交易系统曾因 “网络波动” 导致交易失败,当时排查耗时 2 小时,事后运维团队整理此次历史告警(网络延迟、交易超时、服务器丢包告警),总结出 “网络波动故障” 特征 ——“网络延迟告警先触发,5 分钟后交易超时跟进,伴随丢包”,并制定排查流程(查交换机、链路带宽、跨区域连通性)。半年后类似告警出现,运维人员依 “故障模式库” 指引,20 分钟解决问题。
运维最终目标是保障业务,历史告警是连接“技术指标” 与 “业务价值” 的桥梁。某在线教育平台 “课程播放系统” 频繁触发 “视频加载超时告警”,初期计划增带宽,后分析历史告警与业务数据发现,告警集中在 “移动端非一线城市用户”,且用户网络延迟未超阈值,进一步排查发现超时视频均为 “4K 格式”,移动端网络无法支撑。基于此,技术部门增加 “视频自适应码率” 功能,“加载超时告警” 减少 80%,移动端课程完播率提升 15%。
明确存储内容(告警 ID、时间、级别、类型、关联指标等)、周期(6-24 个月,依业务合规)、方式(时序数据库或分布式存储),通过 “监控数据中台” 整合各系统(服务器、数据库、应用)告警数据,避免 “数据碎片化”,为分析奠定基础。
日常分析:每周 / 每月统计告警数量(按级别、系统、时段)、分析趋势(升降)、排查重复 / 未处理告警,及时发现隐患(如某系统 “磁盘空间告警” 连升两周,需优化清理机制)。
专项分析:重大故障后梳理 “因果链”、总结经验;大促前对比历史告警预测问题、制定预案;架构调整后评估效果(如告警数量是否减少)。
告警数据量增长需依赖工具提升效率:
告警聚合与降噪:通过算法合并重复、关联告警(如同一服务器多个CPU 告警合并),避免 “告警风暴”。
异常检测:基于历史数据建基线,实时数据偏离时预警潜在故障。
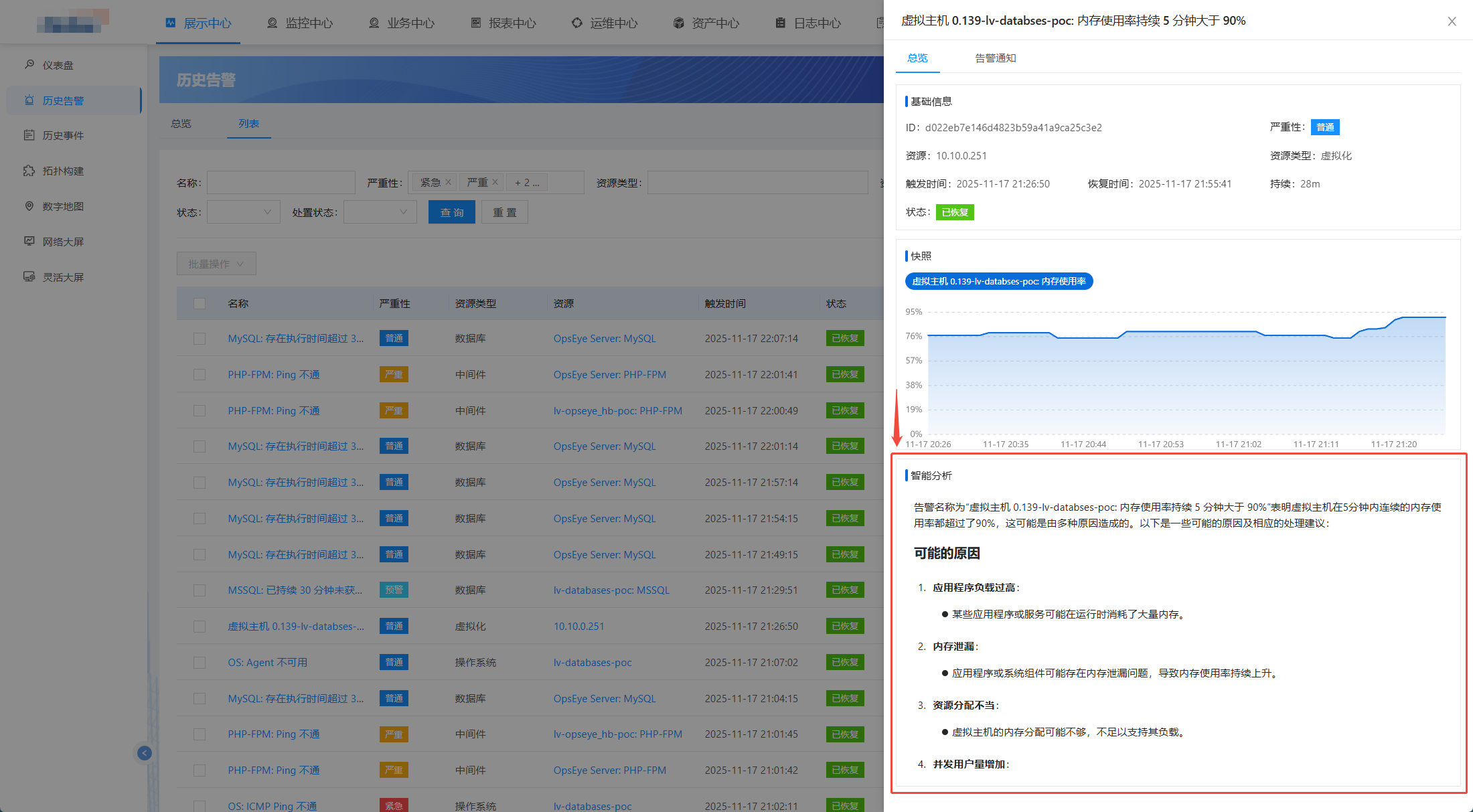
根因分析与处置建议:以 OpsEye智能监控平台历史告警 为例,其将历史告警与 AI 深度融合,借助机器学习对海量历史告警数据进行训练,可自动分析故障发生的深层原因,精准定位问题节点;同时结合历史故障处置案例,生成针对性的处置建议,从 “发现问题” 直接衔接 “解决问题”,大幅降低运维人员决策成本。
数字化时代,IT 系统稳定关乎业务连续与竞争力。实时告警是 “应急眼睛”,历史告警是 “决策大脑”—— 它能助力故障排查、优化资源、支撑业务决策,推动运维从 “被动救火” 转向 “主动预防”。
重视历史告警不是 “额外工作”,而是提升效率、降低风险的 “必要投入”。通过规范存储、科学分析、智能工具,企业可将历史告警从 “被忽视的日志” 转化为 “核心资产”,让运维更具前瞻性与高效性,为数字化转型保驾护航
新闻搜索