Prometheus用了几年,这些坑你注意过没?
三年前,我接手前公司的监控系统时,Prometheus已经运行了大半年。同事留下一句话:"配置都在Git上,有问题看文档。"然后就潇洒离职了。
第一个月还算平静。第二个月开始,问题来了:
凌晨3点被告警吵醒,一看手机:47条未读
Prometheus隔三差五OOM重启
磁盘空间从500GB涨到2TB,还在疯长
查个Dashboard要等10秒,刷新一下又是10秒
更要命的是,真正的P0故障发生时,监控系统居然没告警。等我们发现的时候,用户已经在微博上开骂了。
那段时间我天天熬夜查文档、翻社区帖子、做实验。三年下来,终于把这套系统调教得"听话"了。去年全年,我们只有3次半夜被叫醒,而前年是47次。
今天把那三年踩过的坑、总结的经验,全部分享给你。每一条都是用真金白银(和睡眠时间)换来的。
第一年踩的最大的坑
2022年,我们上线了一个用户行为分析功能。产品经理要求"能按用户维度看每个API的调用情况"。当时没多想,就这么写了:
# 2022年9月,某个"天才"的配置metrics.counter('api_requests_total', {'user_id': user_id, # 当时100万用户,现在300万'endpoint': endpoint, # 200个接口'method': method, # 4种HTTP方法'status': status_code # 50种状态码})
Copy上线一周后,Prometheus开始不定期OOM。我以为是内存不够,申请扩容到32GB,结果第二周又OOM了。
后来找了一位SRE老大哥帮忙排查,他看了一眼配置就笑了:"你这时间序列数得有多少啊?。"
算了一下:时间序列数 = 300万 × 200 × 4 × 50 = 1200亿条
虽然实际不会这么多(很多组合不存在),但活跃时间序列也达到了5000万条。Prometheus的内存模型是:每个时间序列约占3-5KB内存,5000万条就是150-250GB。
那天晚上我重构了所有metric定义,第二天Prometheus的内存占用从32GB降到4GB。
三年后的原则
现在我给团队定了一条规矩:
Label的唯一值数量(Cardinality)必须 < 100,违者代码不准合并。
# 现在的写法metrics.counter('api_requests_total', {'endpoint': endpoint, # 200个接口'method': method, # 4种HTTP方法'status_class': status//100 # 只记录2xx/3xx/4xx/5xx})# 高基数信息全部扔到Trace和日志span.set_attribute('user_id', user_id)logger.info('api_call', {'user_id': user_id, 'trace_id': trace_id})
自查三问(这是我被炸怕后总结的):
这个label的唯一值会超过100个吗?
用户量/请求量增长10倍,这个label会爆炸吗?
去掉这个label,我还能定位70%的问题吗?
如果答案是:是/是/是 → 这个label就不能要。
一句话总结:Label是用来聚合的,不是用来区分每条数据的。如果你的label像身份证号一样每条都不同,那就是设计错了。
第一年的告警泛滥
刚接手监控系统时,我秉承着"宁可错杀一千,不可放过一个"的原则,疯狂加告警规则:
CPU > 60% → 告警
内存 > 70% → 告警
磁盘 > 50% → 告警
API响应时间 > 100ms → 告警
MySQL慢查询 > 1秒 → 告警
Redis连接数 > 50% → 告警
... 一共97条规则
结果是什么?每天收到200-300条告警。值班群的日常就是:
03:17 [告警] node-23 CPU超过60%03:19 [告警] MySQL慢查询数量增加03:23 [告警] Redis连接数超过阈值03:25 [告警] API /user/info 响应时间超过100ms...07:30 某同事:"又是平安无事的一夜呢"
大家对告警已经完全麻木了。真正的P0故障发生时,淹没在一堆P3/P4告警里,直到用户投诉才发现。
去年Q2有次复盘会,老板问:"我们的监控系统到底有没有用?"那一刻我突然意识到,问题不在于监控不够,而是监控太多了。
第二年的大刀阔斧
2023年7月,我狠心把告警规则从97条砍到7条,后来又优化到5条:
groups:- name: critical_onlyrules:# 1. 用户无法使用(错误率高)- alert: HighErrorRateexpr: |sum(rate(http_requests_total{status=~"5.."}[5m])) by (service)/ sum(rate(http_requests_total[5m])) by (service) > 0.01for: 5mannotations:summary: "{{ $labels.service }} 错误率超过1%"runbook: "https://wiki.company.com/runbook/high-error-rate"# 2. 用户体验差(高延迟)- alert: HighLatencyexpr: |histogram_quantile(0.99,rate(http_request_duration_seconds_bucket[5m])) > 0.5for: 5m# 3. 服务完全挂了- alert: ServiceDownexpr: up{job=~"api-.*"} == 0for: 1m# 4. 马上要出问题(磁盘快满)- alert: DiskCriticalexpr: |(node_filesystem_avail_bytes / node_filesystem_size_bytes) < 0.10for: 5m# 5. 关键依赖挂了(数据库、Redis等)- alert: CriticalDependencyDownexpr: |probe_success{job="blackbox", target=~"mysql|redis|mq"} == 0for: 2m
Copy砍掉的那92条规则呢? 全部做成Grafana Dashboard,不发告警,只是"可视化"。想看就去看,不想看也不会骚扰你。
三年后的判断标准
现在判断一个告警是否有必要,我有三个标准(缺一不可):
1. 可执行性 - 收到告警,我能立刻知道该做什么
有Runbook文档?有应急预案?
如果只能"再观察一下",那就不该告警
2. 用户影响性 - 用户真的受影响了吗?
CPU 90%但用户无感知 → 不告警
边缘功能挂了但核心流程正常 → 不告警
只有1%用户受影响但他们是VIP → 要告警
3. 紧急性 - 需要现在立刻马上处理吗?
磁盘80%(还能撑3天)→ 邮件通知
磁盘95%(2小时后会满)→ 短信通知
服务宕机 → 电话轰炸
去年全年,我们半夜被叫醒的次数:3次。每一次都是真正的P0故障,每一次都需要立刻处理。
一句话总结:半夜把你吵醒的告警,必须是那种“不处理的话,明早CEO会在群里@所有人”的级别。
第一年差点背锅的事故
2022年双十一,我守着监控大盘,看着一切指标都很"健康":
平均响应时间:82ms ✅
P50延迟:55ms ✅
P99延迟:198ms ✅
错误率:0.28% ✅
我在值班群发了句:"系统状态良好,各位辛苦了。"
结果10分钟后,客服部门在大群里炸了:"大量VIP用户投诉登录超时!技术部是不是在摸鱼?"
我当时懵了,立刻去查日志,发现了真相:
普通用户(占流量的90%):平均响应时间: 50msP99: 120ms成功率: 99.8%VIP用户(占流量的10%):平均响应时间: 650msP99: 30秒(超时)成功率: 40%(大量超时)
P99指标看起来正常,是因为VIP用户占比太小,被90%的正常请求"稀释"了。
那天晚上我被叫到会议室解释情况,差点背锅。幸好后来查出来是某个第三方OAuth服务针对我们VIP流量的限流策略变了,不是我们的问题。
但这件事给我敲响了警钟:平均值会说谎,P99也会。
第二年开始的改变
从那以后,我们建立了多维度监控:
# 不只看整体P99histogram_quantile(0.99,rate(http_request_duration_seconds_bucket[5m]))# 还要按用户等级拆分histogram_quantile(0.99,rate(http_request_duration_seconds_bucket[5m]))by (user_tier) # VIP/普通/访客# 甚至看更极端的分位数histogram_quantile(0.999, ...) # P99.9histogram_quantile(0.9999, ...) # P99.99
更重要的是,我们建立了三层数据体系:
Prometheus (聚合指标)↓ 发现异常Jaeger (分布式追踪)↓ 定位链路ELK (详细日志)↓ 还原现场
现在出问题时的排查流程:
Prometheus发现"P99突然升高"
按维度拆分,发现是"华东地区 + iOS设备"的组合
在Jaeger里找到这些请求的TraceID
去ELK里搜索TraceID,看详细的请求参数和响应
一句话总结:聚合指标只能告诉你"不太对劲",具体哪里出问题,还得靠Trace和日志去查。
第二年最刻骨铭心的故障
2023年3月某个周五下午,某个核心服务突然开始出现大面积超时。所有监控指标都显示"缓慢恶化",但就是找不到根因:
CPU在缓慢上升(从30%到60%)
数据库连接数在增加(从200到500)
响应时间在变慢(从100ms到800ms)
但没有任何突变点。
我带着团队查了2个小时:
检查了数据库慢查询 → 没问题
看了Redis缓存命中率 → 正常
查了下游服务的响应时间 → 都正常
甚至怀疑是不是被DDoS了 → 流量正常
到晚上7点,某个测试同学突然问:"今天下午谁发版本了?我看Jenkins有记录。"
我一查发布系统:
14:30 - service-a v3.2.1 发布(张XX)14:45 - 故障开始出现
立刻回滚,30秒后系统恢复正常。
那个周五晚上,我一个人在办公室坐到10点。如果发布记录能显示在Grafana上,我能省2小时的排查时间。
第三年开始的改进
现在我们的CI/CD流程里,强制要求所有变更都打到Grafana的Annotation:
# 在Jenkins Pipeline里加一步stage('Report to Grafana') {steps {script {sh '''curl -X POST http://grafana:3000/api/annotations \-H "Authorization: Bearer ${GRAFANA_TOKEN}" \-H "Content-Type: application/json" \-d "{\\"time\\": $(date +%s)000,\\"tags\\": [\\"deployment\\", \\"${SERVICE_NAME}\\"],\\"text\\": \\"Deploy ${SERVICE_NAME} ${VERSION} by ${BUILD_USER}\\"}"'''}}}
在Grafana上显示为垂直虚线,一目了然:
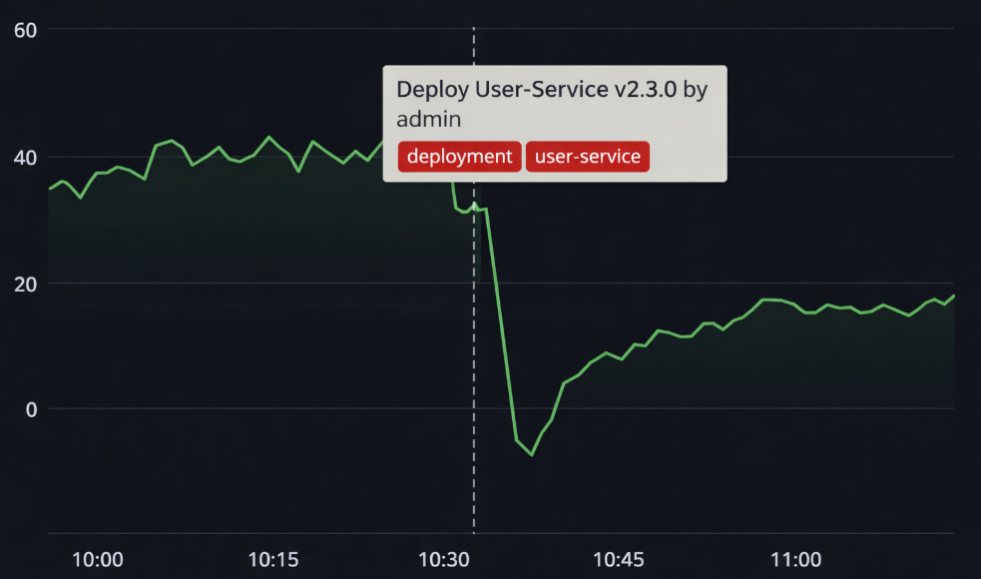
现在的排查流程变成:
看到某个指标异常
第一反应:看Annotation,最近有什么变更?
99%的情况下,都能快速定位
去年统计了一下,我们的故障:
72%与代码发布有关
15%与配置变更有关
8%与基础设施变更有关
只有5%是"真正的未知问题"
一句话总结:故障排查的第一问不应该是"CPU高不高",而是"最近改了什么"。把变更可视化,能省掉90%的定位时间。
第一年的"土豪级别"配置
刚接手Prometheus时,我看到配置文件里写着:
storage:tsdb:retention.time: 365d
我当时想:"这个前同事还挺有前瞻性的,保留一年数据,做年度对比肯定有用。"
半年后,云平台发来账单:磁盘费用从每月¥800涨到¥4200。
我去查了一下磁盘占用:
2022年3月: 500GB2022年9月: 2.8TB2023年3月: 预计会到5TB
问题是,这些历史数据真的有人看吗?
我统计了一下Grafana的查询记录:
查询最近1天的数据:占95%
查询最近7天的数据:占4%
查询最近30天的数据:占0.8%
查询30天以前的数据:占0.2%,而且都是我自己在测试
换句话说,我们花了大量的钱,存储了99.8%的时间里都不会被查询的数据。
第二年开始的分层存储
现在我们的策略是分层存储 + 降采样:
# 第一层:Prometheus本地(热数据)retention.time: 15dscrape_interval: 15s# 存储:高精度原始数据# 用途:实时告警、故障调试# 第二层:Thanos/VictoriaMetrics(温数据)retention: 90ddownsampling: 5m# 存储:5分钟粒度# 用途:周报、月报、趋势分析# 第三层:S3冷存储(冷数据)retention: 1ydownsampling: 1h# 存储:1小时粒度# 用途:年度对比、合规审计
优化效果对比:
优化前:- 总存储:3TB SSD- 月成本:¥4200- 查询速度:8-15秒(扫描海量数据)优化后:- 热存储:200GB SSD (¥300)- 温存储:500GB SSD (¥500)- 冷存储:2TB S3 (¥150)- 月成本:¥950- 查询速度:< 1秒(只查热数据)省下的¥3250/月够团队吃好几顿了
一句话总结:你真的需要知道"去年今天凌晨3点17分的QPS"吗?大部分时候,小时级的趋势图就够了。把钱花在刀刃上。
第二年的性能瓶颈
2023年Q2,我们团队的服务数量从20个增加到80个。Dashboard也越来越多,一共做了40个。
问题来了:每次打开Dashboard要等8-15秒,有些复杂的甚至要30秒。
我去看了一下Prometheus的查询日志,发现有几个查询特别耗时:
# 某个Dashboard的查询sum(rate(http_requests_total[5m])) by (service, endpoint, method, status)/sum(rate(http_requests_total[5m])) by (service)* 100
这个查询每次要:
扫描1000万+时间序列
计算5分钟的rate(300个数据点)
做多层聚合和除法运算
耗时:8-12秒
更要命的是,这个Dashboard被设置成了"团队首页",每个人打开Grafana就会自动刷新。结果就是Prometheus一直在高负载运行,其他正常的查询也被拖慢了。
第三年的解决方案
很简单:用Recording Rules预计算。
# prometheus.ymlgroups:- name: api_performanceinterval: 30s # 每30秒计算一次rules:# 预计算:每个服务的总请求速率- record: job:http_request_rate:5mexpr: sum(rate(http_requests_total[5m])) by (service)# 预计算:每个服务的错误率- record: job:http_error_ratio:5mexpr: |sum(rate(http_requests_total{status=~"5.."}[5m])) by (service)/job:http_request_rate:5m
Dashboard直接查预计算好的指标:
# 优化后的查询job:http_error_ratio:5m * 100
效果对比:
优化前:- 查询时间:8-12秒- Prometheus CPU:长期70-80%- 用户体验:转圈圈,怀疑网络卡了优化后:- 查询时间:< 200ms- Prometheus CPU:降到20-30%- 用户体验:秒开- 额外收益:存储空间反而更小了(预聚合)
适用场景总结:
✅ 适合用Recording Rule的:
Dashboard核心图表(每天被查100+次)
复杂的多层聚合
告警规则里的复杂计算
❌ 不适合的:
临时调试查询
低频查询(一周才看一次)
需要灵活调整的探索性查询
一句话总结:如果一个查询每天要跑100次,那就别让Prometheus每次都重新算一遍。提前算好存起来,后面直接取结果就行。
第三年最惨痛的教训
2024年4月某个周末,Prometheus主实例因为OOM崩溃了。重启花了5分钟。
这5分钟里发生了什么?
所有告警规则失效
某个核心服务出了问题(数据库主从切换失败)
团队在完全盲飞的状态下处理故障
等Prometheus重启后,发现错过了5分钟的关键数据
更糟的是,因为没有告警,我们是20分钟后从用户投诉才知道出问题了。
那次事故的复盘会上,老板问了一句话,我到现在还记得:
"我们花了这么多精力做监控,结果监控系统挂了,我们就变瞎子了?"
那一刻我意识到:监控系统的可靠性,必须高于被监控的系统。
第三年开始的架构改造
很多人以为高可用就是"部署2个Prometheus实例"。但这样会有问题:
❌ 错误的做法:
prometheus-1 → 抓取所有targetprometheus-2 → 抓取所有target(完全重复)问题:- 数据重复,浪费2倍资源- 告警重复,收到2条一样的告警- 两边配置容易漂移(手动同步容易出错)
我们现在用的是Prometheus HA + Alertmanager去重:
# 2个Prometheus实例,相同配置(通过GitOps同步)prometheus-1:external_labels:replica: 1prometheus-2:external_labels:replica: 2# Alertmanager自动根据alert fingerprint去重alertmanager:route:group_by: ['alertname', 'cluster', 'service']group_wait: 10sgroup_interval: 10srepeat_interval: 4hinhibit_rules:- source_match:alertname: 'ServiceDown'target_match_re:alertname: '.*'equal: ['service']
一句话总结:监控系统挂了,就像飞机仪表盘黑屏——你还能飞,但是蒙着眼睛飞。监控系统不能成为单点故障。
三年总结:监控是持续优化的过程
三年前我以为:"把Prometheus装上,配置好,就万事大吉了。"
现在我明白:监控系统和业务系统一样,需要持续迭代、优化、重构。
给你一个月度检查清单:
□ Label Cardinality是否爆炸?(查看cardinality排行榜)
□ 是否有新增的无效告警?(查看告警触发但无人处理的记录)
□ 是否有聚合指标掩盖了真实问题?(回顾上个月的故障)
□ 变更记录是否完整?(抽查几次发布是否有annotation)
□ 存储成本是否合理?(查看磁盘增长趋势)
□ 是否有慢查询?(查看query_duration指标)
□ Prometheus本身是否健康?(查看其自身的监控指标)
最后一句话:好的监控系统,不是让你看到所有数据,而是让你在出问题时,能最快找到答案。
新闻搜索